入力フォームを作る時にこいつの文字数の扱いに苦しみませんか?そう「絵文字」です。
絵文字の文字数をどうやって「正確に」数えてアプリケーションを作るか、という問題と戦った話です。
要件
500文字を入力出来るフォームがあり、ライブバリデーションで文字カウントを行っている。
ある日ユーザからクレームが入る。
「フォームに絵文字「👩👩👧👧」を入れると文字カウントがおかしくなる。」
「絵文字1個しか入れてないのに7文字になっている!正しくカウントしてくれ!」

環境
結合された絵文字
システム界には極悪な文字が存在する。
人間が識別出来る1文字がプログラム上とんでもない文字数になる文字があり、絵文字とかがその代表。
何が困るか?
ユーザが文字と識別する文字とシステムが文字と識別する文字で乖離が生じる。
これによってシステム設計がややこしくなる。
Unicode 絵文字にまつわるあれこれ (絵文字の標準とプログラム上でのハンドリング) / @_sobataro
https://qiita.com/_sobataro/items/47989ee4b573e0c2adfc
1文字だけど1文字じゃない絵文字
というわけで改めて
「👩👩👧👧」
これは何文字でしょう?
言わなくても分かると思ったりもしますが、調べるために文字数カウンターに入れて調べてみます
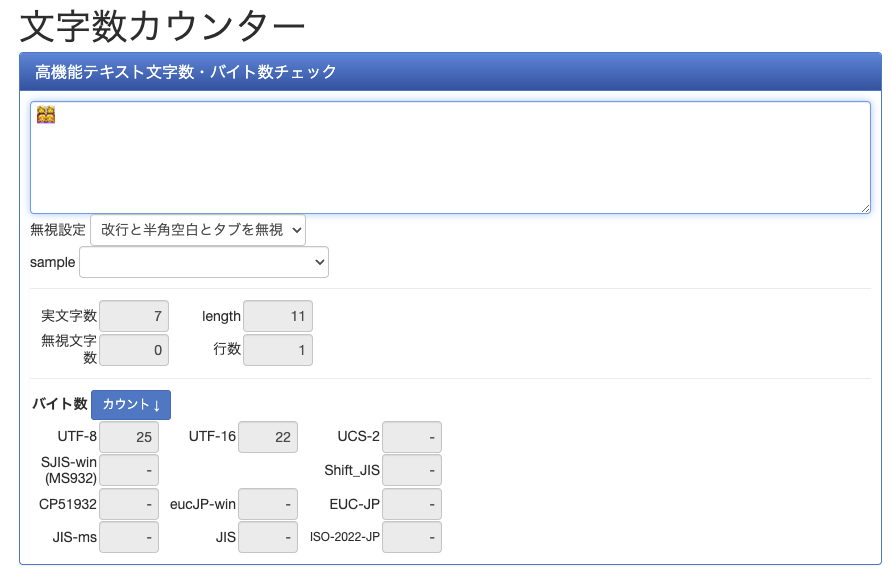
1文字じゃない。7文字です。25バイトあります。
なぜか
Unicode絵文字の仕組みをみてみる / ciscorn
https://zenn.dev/ciscorn/articles/4de71ad0f5b15f
で紹介されてるように
「👩👩👧👧」
の実態は
👩👩👧👧 (family: woman, woman, girl, girl) ← 👩 + ZWJ + 👩 + ZWJ + 👧 + ZWJ + 👧
「family」という絵文字で「woman」と「woman」と「girl」と「girl」をZWJ(ゼロ幅接合子)で繋げて出来た絵文字ということらしい。
それぞれをコードポイントという単位で区切り、文字換算すると「7文字」になる。
普通に見たら
「あ」と「👩👩👧👧」
は同じ1文字と思うでしょ?でもそうもならない。難しい。
絵文字を扱う上でのシステム設計で何が問題か
なんらかの入力フォームがあるシステムが存在するとする。
ユーザは「👩👩👧👧」を1文字として認識して500文字制限のフォームに「👩👩👧👧」を500個入力出来ると期待する。
その期待に答えようとシステム設計をしてみる。
まずはストレージ。今回の環境はRDB(mariadb)「utf8mb4」なので500文字許容できるようにしよう。
単純に文字数で扱うのでVARCHAR(500)カラムを作ってみる。
UTF-8でのVARCHARの数字は「文字数」を表す。
しかし前述の通り1文字に見える「👩👩👧👧」は7文字扱いになる。
500/7 で71文字しか入らず、72文字入れようとするとData too long for columnのエラーになる。
500文字って言ったのに想定と違う・・・ということになる。
まぁでもそれぐらいなら・・・と思ったかもしれないが、極悪な絵文字はまだ存在する。
https://www.unicode.org/Public/emoji/15.1/emoji-zwj-sequences.txt
にある
「👩🏻❤️💋👩🏿」
という絵文字はなんとユーザから見て1文字でも10文字として扱われる。これは500/10 となり50文字しか入らない。もはや詐欺。
仕方ない、そういった時を想定して10文字換算の絵文字を500文字許容出来るようにしよう!
とするならVARCHAR(5000)やらバイト数で65535バイト入るTEXTの選択肢もあるっちゃある。
が、インデックスの貼れるVARCHAR(255)制限や最大値のVARCHAR(16383)の制限、想定しうるケース「👩👩👧👧」500個のようなパターンのために余裕を持った入れ物を用意する設計をしなければならない。
頭が痛いのはストレージの他にフロントエンド、バックエンドでのバリデーションも考慮しなければならないこと。
これはもう1文字の見た目で10文字以上と判定される絵文字も存在する中で、律儀に見た目通りの文字数を許容するシステムを作るか作らないかの話になる。
許容するのが書記素クラスタで判定するシステムで許容しないのがコードポイントで判定するシステムとなるが、コードポイントで判定するシステムの方が作りやすい。まずコードポイントの説明をしてみる。
コードポイントで文字を区切るとはなにか
ということでコードポイントで区切ることを試してみよう。
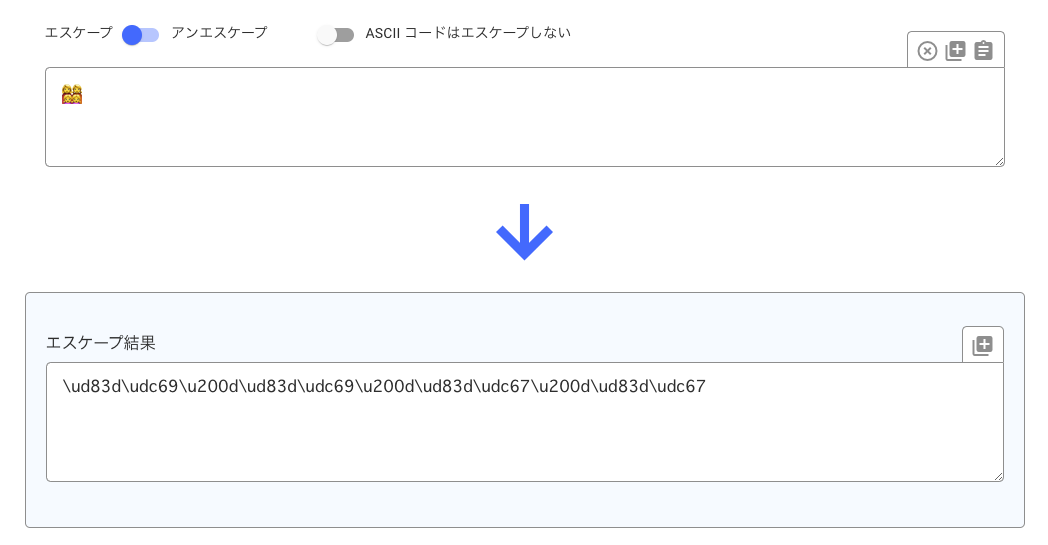
Unicode変換ツールに「👩👩👧👧」を入れてみるとこうなった。
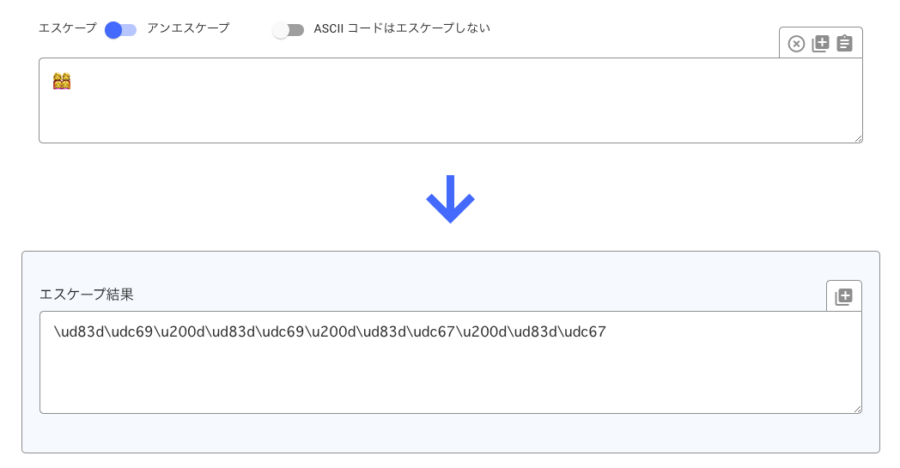
「👩👩👧👧」は「woman + woman + girl + girl」が結合した絵文字で
- \ud83d\udc69\u200d\ud83d\udc69\u200d\ud83d\udc67\u200d\ud83d\udc67
となっている。
よく分からない文字列でこれって何?ということで各絵文字をまず整理して見てみる。
ゼロ幅接合子は
- Unicodeコードポイントで「U+200D」
- Unicodeエスケープシーケンスで「\u200D」
- UTF-8(16進数)で「e2808d」
と表現される。
「👩(woman)」は
- Unicodeコードポイントで「U+1F469」
- Unicodeエスケープシーケンスで「\ud83d\udc69」
- UTF-8(16進数)で「f09f91a9」
と表現される。
「👧(girl)」は
- Unicodeコードポイントで「U+1F467」
- Unicodeエスケープシーケンスで「\ud83d\udc67」
- UTF-8(16進数)で「f09f91a7」
と表現される。
これを見るとこのUnicode変換ツールは絵文字を「Unicodeエスケープシーケンス」に変換してることが分かる。
- \ud83d\udc69\u200d\ud83d\udc69\u200d\ud83d\udc67\u200d\ud83d\udc67
今回やりたいのはコードポイント(Unicodeコードポイント)への変換なので、エスケープシーケンスをコードポイントに変換してから足してあげよう
- 「\ud83d\udc69\」 = 「U+1F469」
- 「\u200d」 = 「U+200D」
- 「\ud83d\udc69\」 = 「U+1F469」
- 「\u200d」 = 「U+200D」
- 「ud83d\udc67\」 = 「U+1F467」
- 「\u200d」 = 「U+200D」
- 「ud83d\udc67\」 = 「U+1F467」
ということで合計7個に分割出来た。これがコードポイント単位の計算で7文字となる。はえーすごい。
1文字の見た目で7文字になるという話を最初していたが、これはコードポイントで判定した結果7文字扱いになるということ。
エスケープシーケンスやらコードポイントやら分かりづらいかもしれにあが、コードポイントで区切るのはこの様に出来る。
ゼロ幅接合子で延々と絵文字をつなげる
話は少し変わるが、ゼロ幅接合子を使えば絵文字を延々と繋げられたりする。
以下はゼロ幅接合子を使って「👨(man)」の絵文字を14個繋げた絵文字。
- 👨👨👨👨👨👨👨👨👨👨👨👨👨👨
コピーをしようと選択すると1文字扱いになる。またバックスペース1回で消える絵文字になっている。
Unicodeエスケープシーケンスに変換して正体を見てみる
- \ud83d\udc68\u200d\ud83d\udc68\u200d\ud83d\udc68\u200d\ud83d\udc68\u200d\ud83d\udc68\u200d\ud83d\udc68\u200d\ud83d\udc68\u200d\ud83d\udc68\u200d\ud83d\udc68\u200d\ud83d\udc68\u200d\ud83d\udc68\u200d\ud83d\udc68\u200d\ud83d\udc68\u200d\ud83d\udc68
こんな感じ。
「\ud83d\udc68\」を「\u200d\」で繰り返し結合しつづけてるだけ。
X(Twitter)の場合どう文字カウントするか ~ 書記素クラスタ~
上記のゼロ幅接合子繋げた自作絵文字だが、システムによってどう扱うかは差が出る。
試しにX(Twitter)のフォームに入れてみると絵文字単位で即座に分割される。
ゼロ幅接合子繋げてるので間にカーソルが入ることはないはずなのだが、フォームに書記素クラスタで即時分割する制御でもかけてるのかな?
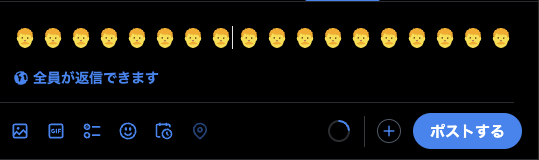
では「👩🏻❤️💋👩🏿」で10文字(35バイト)換算される絵文字を入れてみる。
X(Twitter)の文字数制限は全角140文字のはずなので14文字しか入らない・・・?あれ
予想とは裏腹にめっちゃ入ってる。
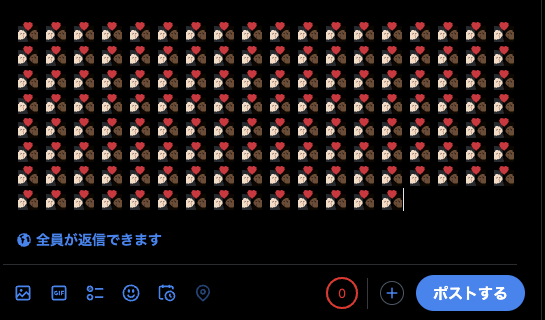
入力フォームにギリギリ入るサイズを確認。1400文字(4900バイト)。
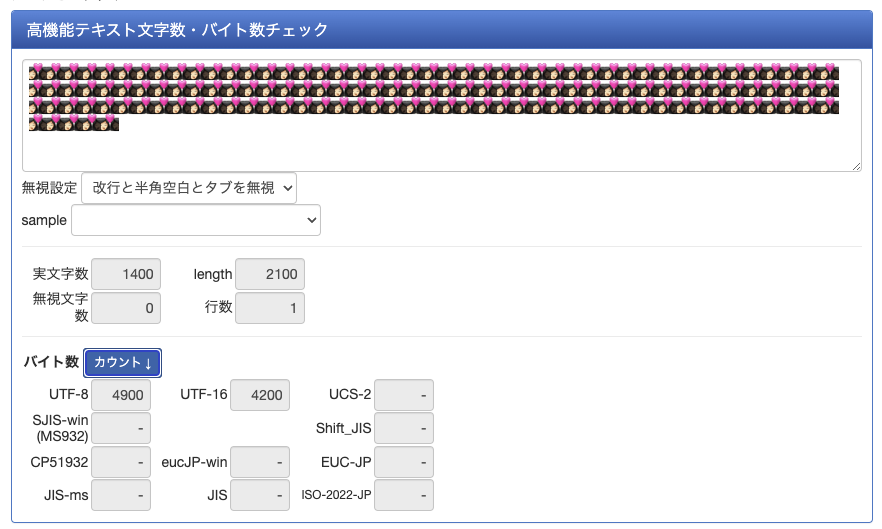
1400÷10で140文字。なのでこの絵文字1個をちゃんと1文字と換算してる!すごい!
やはりコードポイントではなく書記素クラスタで絵文字をカウントしてるのか。
書記素クラスタ (grapheme cluster) ってなんだ
書記素クラスタと呼ばれるものがある。詳しい説明は以下に。
Unicode 絵文字にまつわるあれこれ (絵文字の標準とプログラム上でのハンドリング) / 書記素クラスタ (grapheme cluster)
簡単に言うとこれ。
書記素クラスタ とは、 unicode において自然な“1文字”を表す単位です
書記素クラスタで文字カウントすることは簡単に言うとUnicodeで管理してる文字かどうかで判定すること。
https://www.unicode.org/Public/emoji/15.1/emoji-zwj-sequences.txt
を見ても分かるように私達が目にしないような新しい絵文字はどんどん作られてUnicodeにおいて1文字と認められていく。
つまり
「👨」
はコードポイントの「1F468」をチェックすれば
Unicode管理下にある1文字の絵文字と判定することができる。
「👩🏻❤️💋👩🏿」
もコードポイントの
「1F469 1F3FB 200D 2764 FE0F 200D 1F48B 200D 1F469 1F3FF」をチェック
Unicode管理下にある1文字の絵文字と判定することができる。
しかし
「👨👨👨👨👨👨👨👨👨👨👨👨👨👨」
は「1F468 200D 1F468 200D 1F468 200D………..」というコードポイントになるが、
この全部をまとめたコードポイントに該当するUnicode管理下にある絵文字は存在しないので1文字判定は出来ない。
するとしたら「1F468」ずつ区切られることになりX(Twitter)のフォームのように「👨」毎に区切ることになる。
書記素クラスタとコードポイントどっちで文字カウントする?
ここまでで書記素クラスタの簡単な説明をしたが、これを用いればコードポイントより厳密に文字カウントは出来る。
「👩🏻❤️💋👩🏿」はコードポイントで見れば10文字扱いだが、書記素クラスタで見れば1文字扱い。
書記素クラスタで判定すればよりユーザの認識に近い文字カウントが出来るが、前述した通りデータを保存するストレージがネックになる。
X(Twitter)の例だと140文字制限がかかるフォームなので「👩🏻❤️💋👩🏿」だけを考えると4900バイト入ることを保証しておかなければいけない。
また、絵文字に関してはUnicode標準が増えていき、1文字でかなりのバイト数を持つものが誕生し続けている。
ちなみにX(Twitter)が現状の動きを実現出来てるのはストレージがNoSQL(Cassandra->Manhattan)だから。
RDBを使わざるを得ないシステムとは分けて考える必要がある。。
結論
RDBを使う今回のシステムでは「👩👩👧👧」のような絵文字をプログラム上で書記素クラスタで判定(1文字として扱う)することは諦めた。
ストレージを書記素クラスタ対応で作成したとしても、フロントとバックエンドで適切なバリデーションを行いたいことを考えると今回は対応コストが高すぎた。
今回はプログラム上では「コードポイント」で文字カウントを行うことにする。
コードポイントであればライブラリは偉大なる先人たちが頑張って作ってくれている。
- フロントのバリデーションは[…str].lengthを採用。
- バックエンドのバリデーションはHibernateValidatorのCodePointLengthを採用。
これでRDBで安心してVARCHAR(500)でカラムを作ることができる。
何を正しい絵文字の数え方にするか、というのは仕様や要件次第でもあるが、絵文字1個を1文字としてカウントしてバリデーションをかけてあげるということは文字数上限が増えるにつれ難しい。
何も知らないユーザ目線では「文字カウントおかしい」となるがそこはきっぱり諦める方がコストは低くなる。
そもそも文字カウントを律儀に表示するのは親切のように見えるがよくないかもしれない。
ユーザはフォームに「入力したい文字を入力する」事がやりたいのであって、絵文字、合字、結合文字を正確にカウントされることが目的とは言い難かった。細かい制限はマニュアル等でカバーしよう。
フォームのライブバリデーションはするがカウントは表示しないというのがいいかもしれない。文字上限を超えたら潔く文字数を削ってもらう方向にしよう。
参考
Unicode 絵文字にまつわるあれこれ (絵文字の標準とプログラム上でのハンドリング) / @_sobataro
https://qiita.com/_sobataro/items/47989ee4b573e0c2adfc
Kotlin / Swift での Unicode の扱いまとめ (見た目上の文字数カウント, UTF-8, UTF-16, BOM, 正規化, 異体字セレクタ) / @irgaly
https://qiita.com/irgaly/items/5decdbf5ed89f9cf2c27
絵文字👨🏻🦱は何文字としてカウントする?関連する文字コードの仕様を詳しく調べてみた / @comware_harase
https://qiita.com/comware_harase/items/59c60ab1c6e1797f0821
[DBデザイン#47] VARCHARとTEXTどちらを使う? / Blog by msyk
https://blog.msyk.net/?p=1548
見た目で区別できない変数 / ++C++;
https://ufcpp.net/blog/2020/5/variationselectoridentifier/
Unicodeのgrapheme cluster (書記素クラスタ) / hydroculのメモ
https://hydrocul.github.io/wiki/blog/2015/1025-unicode-grapheme-clusters.html
FamiliEmojis.cs /ufcpp
https://gist.github.com/ufcpp/2b44f6c7f5e3d4d7e39f2f6bd1d1f8bb
【図解】【3分解説】UnicodeとUTF-8の違い!【今さら聞けない】/ @omiita(オミータ)
https://qiita.com/omiita/items/50814037af2fd8b2b21e
Unicode絵文字の仕組みをみてみる / ciscorn
https://zenn.dev/ciscorn/articles/4de71ad0f5b15f

コメント