「Spring bootで多言語対応に使っているpropertiesファイルに記述してあるメッセージに対して、特定の文字を使ってる部分を抜き出してまとめたい。」
という要望があった。
Intellij IDEA等エディタでは設定で普通に見れたりするが、普通に開くと「\u713c\u8089」のような読めない文字が表示される。
【解説付き】IntelliJ IDEAでpropertiesファイルの文字化け表示を直す方法(Mac) / @growsic
https://qiita.com/growsic/items/c611e29313f09246c2d0
Intellij IDEAで日本語で検索をかける分には上記で問題なく出来る。
ただ、propertiesファイル自体に直接検索をかけるとUTF-8で保存されてないので検索にかからなくなる。困った。
今回はお手軽に一つにまとめるためにしたことを書いていく。
Unicodeエスケープシーケンス(ASCII文字)をgrepするのはひと手間かかる
単純にgrepかければいいのでは、と最初に思ったのだが何回やっても引っかからない。
多言語化対応のpropertiesファイルはUnicodeエスケープシーケンス(ASCII文字)で保存されていた。
intellij IDEAのエディタ上で私達が見えるようになっているのはエディタが変換してくれているから。
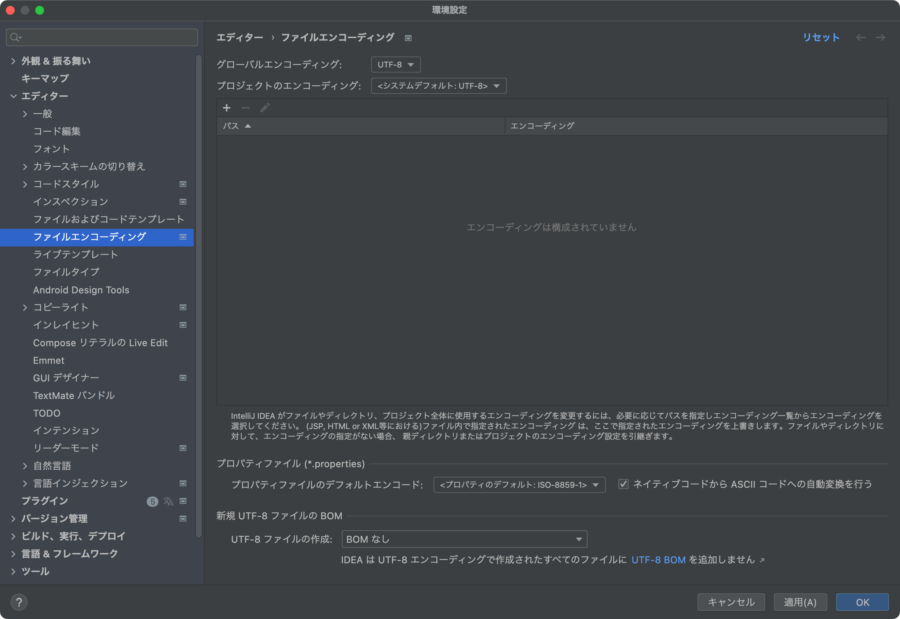
Preferences -> ファイルエンコーディング -> 「ネイティブコードからASCIIコードへの自動変換を行う」
にチェックが入ってれば勝手に変換して保存、変換して表示してくれるのであまり意識はしない。
Unicodeエスケープシーケンスでgrepをかけるしかない
つまり、propertiesファイルに「焼肉」とかかれた記述があっても、単純にgrepで「焼肉」をそのまま検索しただけではヒットしない。
Unicodeエスケープシーケンス(ASCII文字)文字でgrepするしかない。ちなみに厳密には「ISO8859-1」という文字コードらしい。
grepしたい文字のUnicodeエスケープシーケンスを取得する
まず初めに検索をかけたい文字列をUnicodeエスケープシーケンス(ASCII文字)に変換する。
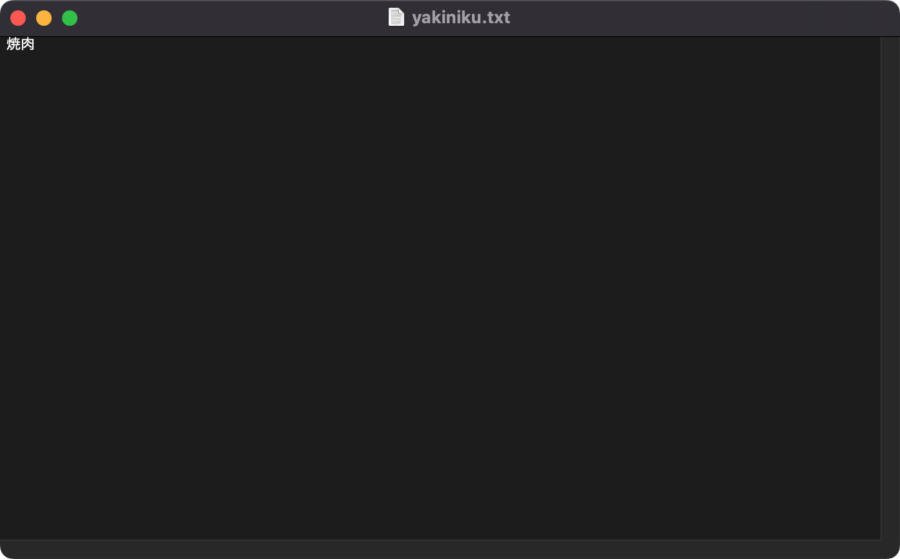
適当にtxtファイル(yakiniku.txt)を作成し、そこに抽出したい文字列を記述して保存する。
今回は「焼肉」と打ち込んだファイルを用意。
native2asciiコマンドを使用して変換する
JDKに付属するnative2asciiコマンドを使用する(パスが通っていれば下記のコマンドで叩けるはず)
$ java --version // 自分の環境はこんな感じ。 openjdk 11.0.13 2021-10-19 LTS OpenJDK Runtime Environment Microsoft-27990 (build 11.0.13+8-LTS) OpenJDK 64-Bit Server VM Microsoft-27990 (build 11.0.13+8-LTS, mixed mode)
JDKバージョンによってはnative2asciiが入ってなくて叩けない場合もあるので注意。
(上記環境は入っている)
native2ascii コマンドで文字を変換する
ファイル名は「変換したいファイル」と「変換後のファイル名」を指定。
ちなみに変換後のファイルは存在しなければ作成される。
$ native2ascii -encoding UTF-8 ~/Downloads/yakiniku.txt yakiniku2.txt
作成されたファイルを開くとこんな感じ。「焼肉」が「\u713c\u8089」に変換されている。
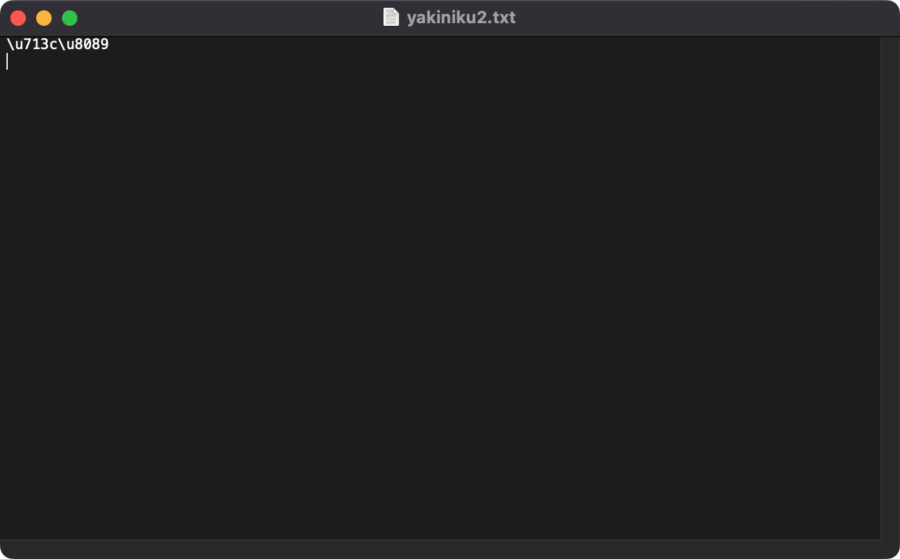
これがASCII文字。
用意したUnicodeエスケープシーケンスでgrepする
findとgrepコマンドを使ってgrepしていきます。
はじめにgrepするアプリ配下に移動しておきます。
$ cd ~/myApp/moge-app/
その後下記のコマンドを実行するだけです。
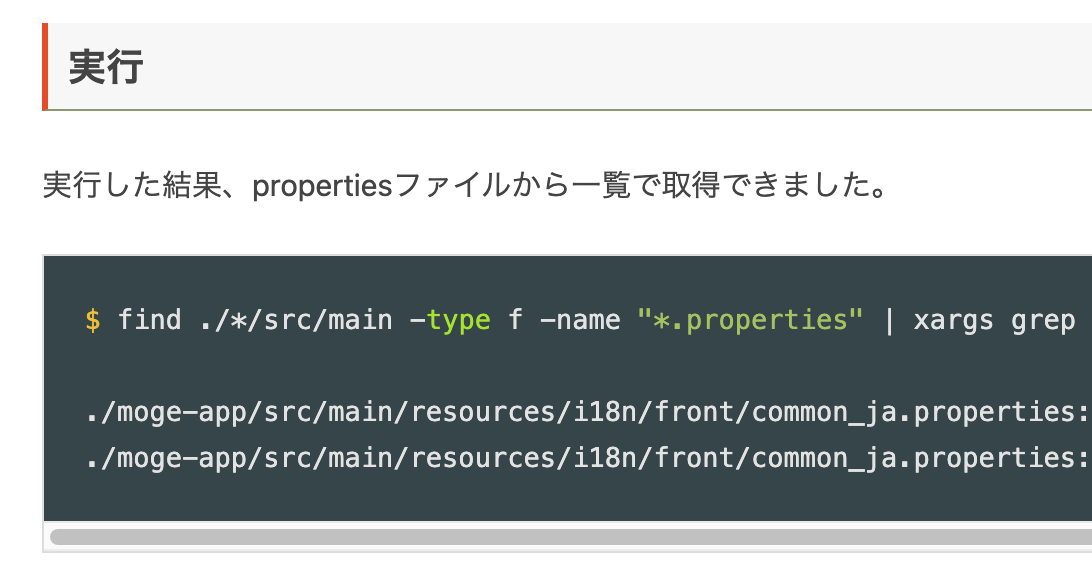
$ find ./*/src/main -type f -name "*.properties" | xargs grep -iF "\u713c\u8089"
find (ディレクトリ指定)
/out/mainのようなディレクトリが混じると困るのでディレクトリは./*src/mainで指定しています。
find -type f -name ファイル+ファイル名指定
propertiesファイルに対して検索かけるので拡張子を指定しています。
grep -i
native2asciiコマンドとintellijの変換で大文字小文字の差異が出たのでオプションで大文字小文字を区別しないようにします。
grep -F
正規表現で使う文字をエスケープせずに検索すします。
検索対象はダブルクォーテーションで囲う。これでスラッシュをエスケープせずに済みます。
実行
実行した結果、propertiesファイルから一覧で取得できました。
$ find ./*/src/main -type f -name "*.properties" | xargs grep -iF "\u713c\u8089" ./moge-app/src/main/resources/i18n/front/common_ja.properties:front.common.menu.lunch=\u713C\u8089\u5B9A\u98DF ./moge-app/src/main/resources/i18n/front/common_ja.properties:front.common.menu.house=\u713C\u8089\u5FA1\u6BBF
grepした結果を再変換する
grep出来ましたが、これでは何が書いてあるかわかりません。取得した結果を私達が読めるように再変換します。
reverse-yakiniku.txtというファイルを作ってgrep結果を貼り付けて保存します。
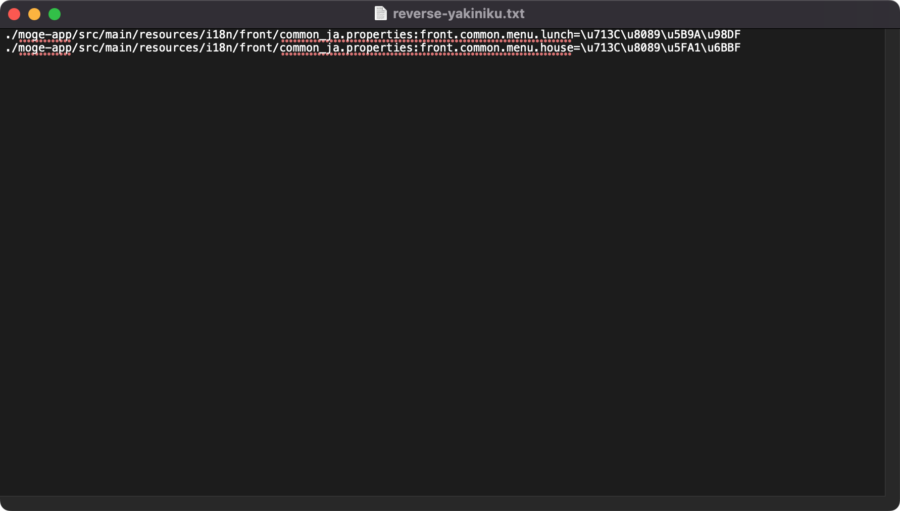
-reverseオプションを使って今度はasciiからUTF-8に変換します。
$ native2ascii -reverse -encoding UTF-8 ~/Downloads/reverse-yakiniku.txt reverse-yakiniku2.txt
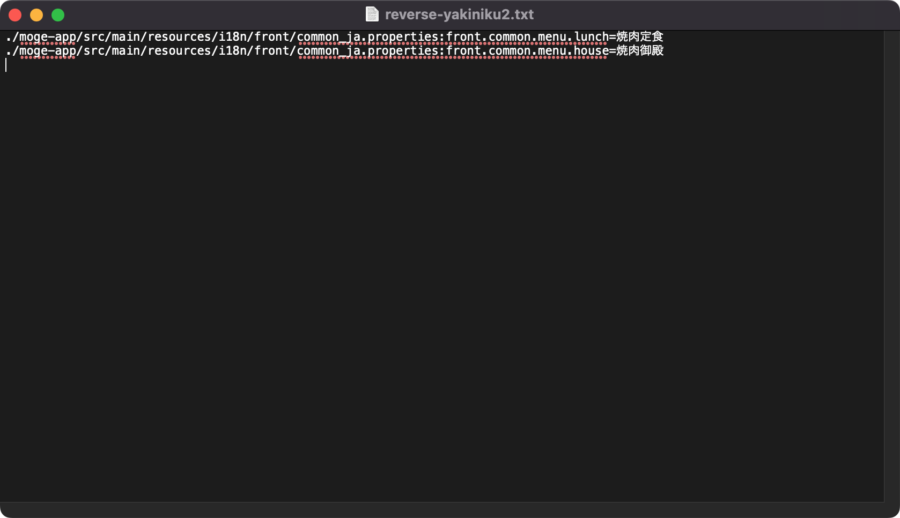
素晴らしい!変換できました!
これで指定の文字列を含むpropertiesファイルの行を抽出してまとめることが出来ました!
環境
- zsh: 5.9 (x86_64-apple-darwin21.3.0)
- spring-boot: 2.7.3
- openjdk: 11.0.13
参考
正規表現で使用するメタ文字を検索するには / @IT 北浦訓行https://atmarkit.itmedia.co.jp/flinux/rensai/linuxtips/549rexsearch.html
【 grep 】コマンド――特定の文字を含む行を抽出する / @IT
https://atmarkit.itmedia.co.jp/ait/articles/1604/07/news018.html
native2ascii コマンドで Unicode 表記の文字列を処理 / Qoosky
https://www.qoosky.io/techs/7f81099035
【解説付き】IntelliJ IDEAでpropertiesファイルの文字化け表示を直す方法(Mac) / @growsic
https://qiita.com/growsic/items/c611e29313f09246c2d0


コメント