文字カウントするときに厄介な絵文字が存在します。例えばこのような「👩👩👧👧」絵文字です。1文字に見えますよね?
でもこれ7文字換算されることもあります。
果たしてどういう仕組みになってるのでしょうか?見てみましょう。
まずは普通の文字をカウントする
まずは試しでテーブルを作ってみる。
create table user ( user_message VARCHAR(50) not null );
NG: カタカナ51文字(3×51 = 153バイト)
カタカナを挿入してみよう。日本語文字は3バイト。
カタカナ51文字(3×51 = 153バイト)を挿入するinsert文を用意して実行してみる。
insert into user( user_message ) values( 'カナヘイカナヘイカナヘイカナヘイカナヘイカナヘイカナヘイカナヘイカナヘイカナヘイカナヘイカナヘイカナヘ' );
結果
Data too long for column 'user_message' at row 1
バイト数は余裕があるが文字数がオーバーしてるので当然エラーが出る。
絵文字をカウントする
NG: 絵文字「🥺」51文字(4×51 = 201バイト)
絵文字「🥺」を挿入してみよう。
1文字4バイトの絵文字を51文字(204バイト)のINSERT文を用意してみた。
insert into user( user_message ) values( '🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺🥺' );
Data too long for column 'user_message' at row 1
同様にエラーが出る。バイト数も文字数もオーバーしているので当然。
NG: 1文字に見える絵文字8個(56文字 200バイト)
では1文字に見える絵文字「👩👩👧👧」はどうなるか。
insert into user( user_message ) values( '👩👩👧👧👩👩👧👧👩👩👧👧👩👩👧👧👩👩👧👧👩👩👧👧👩👩👧👧👩👩👧👧' );
Data too long for column 'user_message' at row 1
これでエラーが出る。8個に見えるがUTF-8だと「👩👩👧👧」が1個で7文字換算で56文字なので文字数オーバーしている。
文字数と聞くと惑わされてしまいそうだ。この絵文字はなんで7文字として計算されるのか?
1文字に見える絵文字「👩👩👧👧」 の文字数をカウントする
カウントがおかしくなる絵文字
今回のデータベースはutf8mb4なので文字数はUTF-8で数えることになる。
人間が識別する単位の数え方ではないことに注意。
まずはじめに「👩👩👧👧」は「woman + woman + girl + girl」が結合した絵文字である。
つまり「👩 + 👩 + 👧 + 👧」ということ。
なるほど、じゃあ絵文字4個だから4文字?・・・・とはならない。
ゼロ幅接合子 での結合されている絵文字の正体
最初に説明した「結合した絵文字」であることを考える。
どういうことか、というと結合するのも「文字」で行っていて「ゼロ幅接合子」というもので行っている。
これはUTF-8(16進数)で表現すると「e2808d」になる。
つまり、「👩👩👧👧」という絵文字は
「👩 e2808d 👩 e2808d 👧 e2808d 👧」
という感じで絵文字の結合がおこなれている。
絵文字とゼロ幅接合子の数をカウントすると7個となる。だから7文字になる。
絵文字をUTF-8で分解してみる
最後に絵文字もUTF-8(16進数)で分解してみよう
- 👩 -> f09f91a9
- e2808d
- 👩 -> f09f91a9
- e2808d
- 👧 -> f09f91a7
- e2808d
- 👧 -> f09f91a7
UTF-8で文字数をカウントするということは上記のような形で区切って数えることになる。
全部まとめると「f09f91a9e2808f09f91a9e2808df09f91a7e2808df09f91a7」こうなる。
なんでこの英数字の羅列と絵文字が対応しているの?というとUnicodeコードポイントで定義されているからである。
絵文字をUnicodeコードポイントで表してみると?
「👩👩👧👧」はUnicodeコードポイントで表すと
- U+1F469
- U+200D
- U+1F469
- U+200D
- U+1F467
- U+200D
- U+1F467
の7個の集まりである。
絵文字をUnicodeエスケースプシーケンスで表してみると?
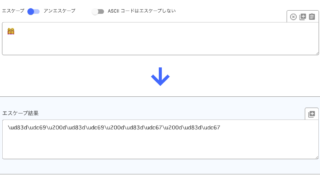
これを扱いやすくするために「👩👩👧👧」をUnicodeエスケースプシーケンスにすると
- \ud83d\udc69
- \u200d
- \ud83d\udc69
- \u200d
- \ud83d\udc67
- \u200d
- \ud83d\udc67
こうなったりする
絵文字をUTF-8(16進数)で表してみると?
これは上記で書いたのと同じだが「👩👩👧👧」をUTF-8(16進数)にすると
- f09f91a9
- e2808d
- f09f91a9
- e2808d
- f09f91a7
- e2808d
- f09f91a7
UTF-8は「Unicode Transformation Format – 8-bit」の略であるようにUnicodeを符号化したものである。
つまりそれぞれ使いやすいように変換してるだけ。
ここらへんは他の記事でも書いたので興味があればどうぞ
まとめ
人間が見てる1文字はシステムの世界では1文字でないかもしれない。
「UTF-8で文字数を数える」というのはUnicodeのコードポイント単位で数えること。

コメント